


Linked Dataで考えるメタデータの繋がりと広がり
- 準備:利用者タスクとRDFグラフ
- 例題:著作リストをつくる
- 試みたタスクと求められる機能
- 利用者タスクの整理
- メタデータの共有と文脈
- RDFグラフによる記述
- Linked Dataと2種類のURI
- アクセスポイントとLOD
- 典拠とアクセスポイント
- 組織・領域を越えるアクセスポイント
- 関連リンクと識別子のハブ
- 正規化辞書にない名前
- アクセスポイントとしてのNDC
- 詳細な記述と構造化
- 多重化された値
- RDFによる構造化データ
- ジャパンサーチ利活用スキーマの記述モデル
- 使いやいアクセス:発見タスクとのバランス
- (参考)Wikidataの記述モデル
- リンクと構造化によるメタデータの拡張
- ジャパンサーチの構造化ノードとLOD
- 全体・部分関係の記述
- 全体・部分関係の記述:構造化と二層モデルの導入
- アイテムと作品:上演の記述モデル
- (構想中)著作リストの作品と出版物
- Linked Dataでできることは
- つながりを活かす
- (構想中)注釈モデルによる引用からのリンク
- 識別子ハブを介した相互検索(統合クエリ)
- 充実そして活性化
- まとめと課題
- 参照先
例題:著作リストをつくる
- ステップ1:山崎正和の著作を探し出す
- 例えばNDLオンラインで著者(=山崎正和)検索
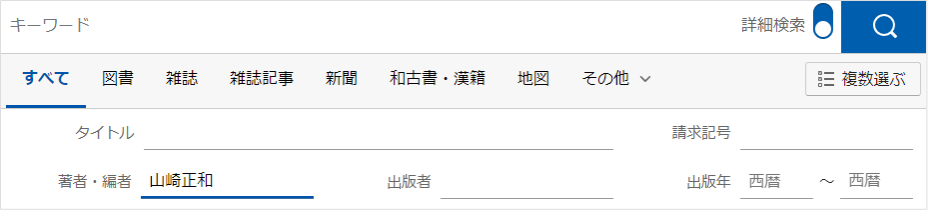
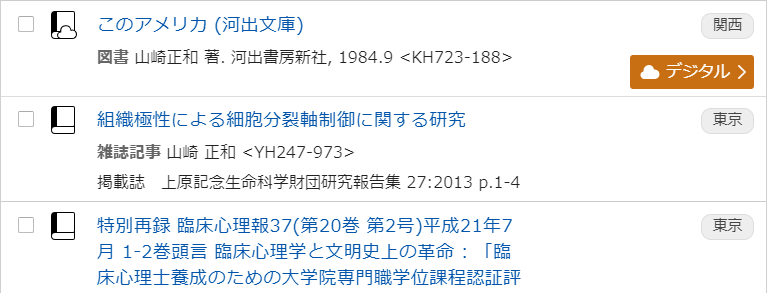
- ステップ2:検索結果からリストに収録する著作を絞り込む
- タイトルや掲載誌を見て明らかに別の山崎正和氏によるものを選び分ける
- 細胞学や臨床心理学の山崎氏は該当する?
- ステップ3:得られた結果をもとに著作リストの雛形を作る
- 結果のデータを何らかの手段で取得し、加工する
- エクスポート機能やAPIがあれば取得手段となる
メタデータの共有と文脈
- 文脈を前提とする記述
- OPACなどの目録詳細は一般に項目:値ペアで表現される
- 対象は詳細ページの表すもの(暗黙の前提)
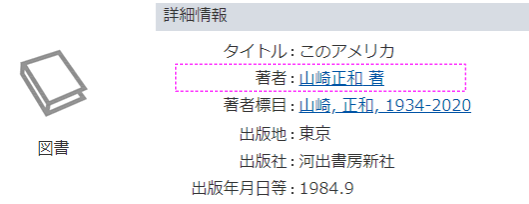
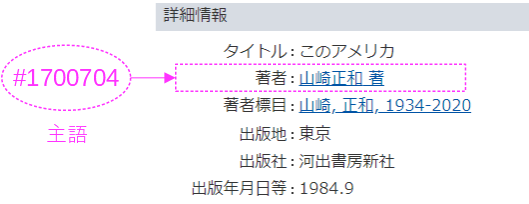
- 文脈に依存しない記述
- メタデータを異なるDBで共有・再利用するには対象の明示が必要
- 対象を主語として項目:値ペアに加えることで文脈に依存せずに表現
RDFグラフによる記述
- RDFトリプルとURI
- 項目:値ペアに主語を加えたRDFトリプルで最小単位の情報を記述
- 主語、述語(項目名)、目的語(項目値)にURIを用いる → ウェブ全体で通じる
- 漢字などを直接用いることができる識別子はIRI(URIの上位互換)だが、ここではIRIと同じ意味でURIを用いる

- RDFリテラルとRDFグラフ
- 数字やラベルそのものなど別途名前を与える必要がないものはリテラル値(=そのまま)とする
- RDFトリプルの集合をRDFグラフと呼ぶ
- 同じURIを持つノードは(誰が記述したものでも)連結できる
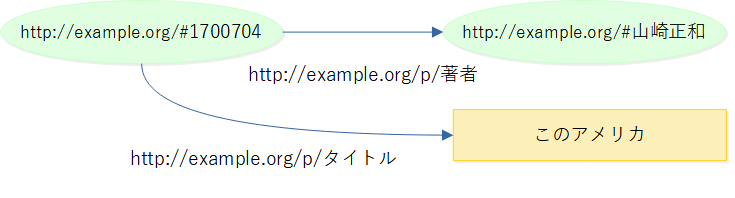
- 共通のURIを広く共有すれば、グラフが繋がり、付加価値が増す
Linked Dataと2種類のURI
- リンクするデータ
- ティム・バーナーズ=リーが2006年にLinked Dataの4原則についてのメモを公開
- URIを識別だけでなくリンクにも用いる=リンクを辿ってRDFが取得できる
- LODはこの考えを公開データに結びつけるもので、2007年のW3CプロジェクトLinking Open Dataが発端
- つまり「リンクする」オープンデータ。その後、一般にはLinked Open Data
- 外部データセットとのリンクは重要だが、同じデータセット内のリンクもLinked Data
- 情報リソースと非情報リソース
- URIを辿って直接情報が得られるものは情報リソース=典拠など
- 人物などネットワーク経由で取得できないものは非情報リソース
- 異なるもの(例えば典拠と人物)に同じURIを与えることはできない(=URIの衝突)
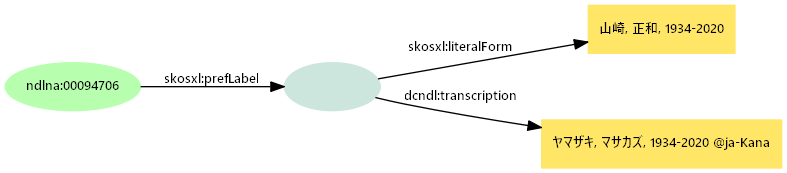
- Web NDLAの典拠と人物
- 典拠URI:http://id.ndl.go.jp/auth/ndlna/00094706
- 典拠作成日、出典など人物とは別の属性を持つ
- 人物URI:http://id.ndl.go.jp/auth/entity/00094706
- 生没年など人物としての属性を持つ
- 著者の記述には人物URIを用いる
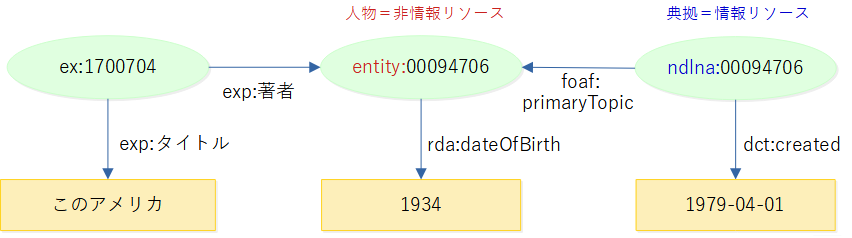
- 典拠URI:http://id.ndl.go.jp/auth/ndlna/00094706
典拠とアクセスポイント
- 典拠レコードの要素
- 統一された名前(統一標目)と識別子ID
- 別名、表記の揺れからのアクセス(異形アクセスポイント)
- ほかの実体との区別=識別のための情報(生没年、分野など)
- 関連する実体とのリンク
- 来歴、根拠、情報源
- (図書館情報学事典2023「典拠コントロール」より。以下で「典拠要素」として参照)
- アクセスポイントの形とURI
- 標目型:山崎, 正和, 1934-2020 → 分かりやすいが改名、没年追加などで変化
- ID型:00094706 → 確実だがラベルなしには使えず、複数典拠が混在すると機能しない
- URI型:http://id.ndl.go.jp/auth/ndlna/00094706 → どこでも確実。典拠レコードRDFの主語にできる
- URIによる典拠の記述
- (概ね)共通の方法でラベルと関連付け(典拠要素1.)

- 以下では長いURIを必要に応じて
rdfs:labelのような形で短縮表記
- 以下では長いURIを必要に応じて
- 他の要素もRDFトリプルで記述し、典拠レコード全体をRDFグラフとする
関連リンクと識別子のハブ
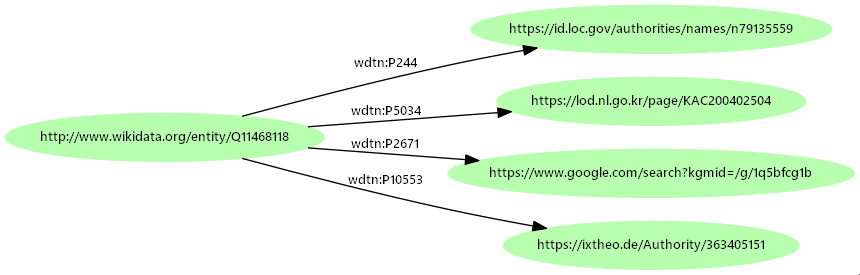
- 複数の典拠(URI)
- 分野ごとに、組織ごとにいろいろな典拠
- アメリカ議会図書館:n79135559
- 韓国国立中央図書館:KAC200402504
- Google知識グラフID:/g/1q5bfcg1b
- 神学索引:363405151
- 関連リンク先(典拠要素4.)としてどの典拠を使うか
- 複数にリンクしてもよいが、どこかに集中できる方が互いにリンクしやすい
- 自前で典拠を持たず外部典拠をアクセスポイントとして使うことも考えられる
- 図書館関係ならVIAFがあるが…
- 分野ごとに、組織ごとにいろいろな典拠
- 識別子のハブとなるWikidata
正規化辞書にない名前
- 値のURI化と典拠
- すべての値を典拠としてURI化できるのが理想
- データセットで用いる典拠にすべての値がマッピングできるとは限らない
- たとえば生命科学の山崎正和氏(秋田大学)はNDLAの典拠IDがないため、NDLサーチのRDFでは空白ノード

- ジャパンサーチの正規化辞書と非統制名
アクセスポイントとしてのNDC
- NDCの版とURI

- NDCの932は、版によって上位分類名が微妙に異なるが基本的に同じ意味
- 分類記号932を表すURIはNDC-LD8/9版、NDL版など現在のところ複数ある
- NDLサーチのRDFでは型付リテラル("932"^^dcndl:NDC8)
- 「エレファント・マン」のNDCは国立国会図書館では8版の932、公立図書館では9版/10版の932が多い
- アクセスポイントとして版次なしURIを直接記述
- Webcat PlusのRDFモデルでは、試験的にNDC-LDの版次なしURIに一本化
- もちろん版によって項目名が異なる分類もあるので、版も確認できる必要がある →
schema:descriptionに導入句「分類: 」に続けて版付分類記号を格納- 「このアメリカ」の914.6は9版以降では「評論.エッセイ.随筆--近代:明治以後」であるのに対し、8版では「評論.小品.随筆--近代」、さらに6/7版では「日記,紀行,随筆,小品.評論--江戸時代」
-
- 考え方としては、後述の構造化を用いて、基本値は版次なしURIとしつつ版情報も併記する方法もある
- 版次なしURIのNDC-LDの定義
- 版次なしURIは9版、8版のNDC-LDの分類定義で
dct:isVersionOfとして記述されているのみ- これだけでは、上位下位関係を利用した集約などができない
- NDC-LD9版の
rdfs:label、skos:broaderを継承、9版にはdct:hasVersionでリンク - さらにWebcat plusで用いられる分類で、NDC-LD9版では定義されていない分類を追加
- 補助区分表による分類(NDC-LDでは部分的に生成)を、実際に使われているものに絞って追加生成(版次なしのみ)
- 第10版での新設、第6/7版からの廃止など第9版にない分類を追加
- 版次なしURIは9版、8版のNDC-LDの分類定義で
多重化された値
- 行為者とその役割などが多重化された責任表示
- 複数の情報を単一項目に押し込むため値が多重化される

- 記述方法が分野によって異なる → 名前と役割の区切りが非専門家では分からない場合も
- 和田英作編、西山元文の「作」「文」は役割文字なのか名前の一部なのか
- さらに複数値が1フィールドに記述されることもあるが区切り文字が不統一
- 同じデータセットで
,が複数値区切りと姓名区切りの両方に用いられたり - "Hearn, Lafcadio, 1850-1904 小泉, セツ"というデータは機械的に分割できるのか
- 同じデータセットで
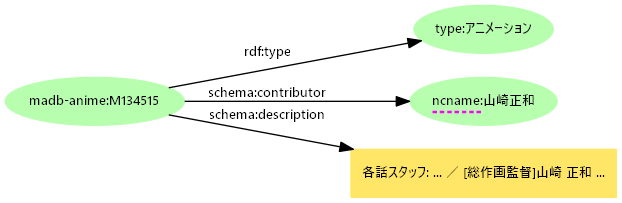
- 分割と項目名
- NDLサーチのRDFではdct:creatorの値としてURI、dc:creatorの値として役割を含む責任表示
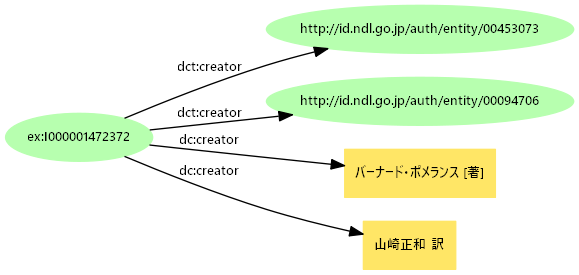
- 役割は人間が読んではじめて分かる。
dct:の値とdc:の値の対応が分からない- 役割ごとに項目(プロパティ)を設定すれば整理できるが
creator バーナード・ポメランス translator 山崎正和 - 多分野メタデータでは際限なくプロパティが増える
- 同一プロパティで検索できない
RDFによる構造化データ
- セットとなる表現

- 表記と読み、筆名と本名、住所分かち書きなど、ひとまとまりとして扱うべき情報
- それぞれのプロパティで直接記述すると、別名や住所が複数ある場合など対応関係が破綻する
- RDFの空白ノードと構造化
- 通常ノードはURIで識別・参照する
- 空白ノード:グラフ内で識別できればOKでグローバルに参照する必要のないノード
- ある(匿名の)ノードがグラフ内に存在することだけ示す
- 空白ノードを節点としてひとまとまりの情報を構造化できる
ジャパンサーチ利活用スキーマの記述モデル
- ジャパンサーチの構造化記述
- ジャパンサーチ利活用スキーマ:200近いデータセットを統一的に記述するためのRDF語彙
- 「いつ」「どこ」「だれ」について、空白ノードを用いた構造化記述を導入
- 正規化値を
jps:valueで、加えてjps:relationTypeでその役割を示す - さらに元データの値も
schema:descriptionで構造化ノードに保持する
- 寄与者(だれ)とその役割のモデル
- アイテム主語とこれらを構造化した空白ノードを
jps:agentialで関連付け- 元項目名を細かなプロパティに分けず、役割として表現。さらに元データ値の導入句としても保存
- 役割の値は責任表示などの役割文字も加味して構造化。「制作」「公開」など大きなくくりで集約可能
- 同じ役割を持つ「いつ」「どこ」と対応付けられる。例えば「公開.出版」で出版者、出版日、出版地(出版イベント)が対応
- 元データは別名や表記揺れを標目に正規化したときなど確認のために必要
- 詳細な関連情報がまとまっている=識別タスクに重要
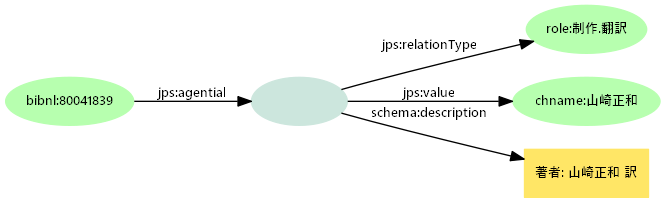
- アイテム主語とこれらを構造化した空白ノードを
使いやいアクセス:発見タスクとのバランス
- 利用者はアクセスポイントを…
- シンプルに考える。対象アイテムの直接のプロパティ値であるというメンタルモデル
- 構造化記述の場合、モデルを知らないと発見タスク(人物名/URIでの検索)がうまくできないかもしれない
- まず試してみる。
dct:creatorなど広く使われるプロパティの確率が高いだろう…
- シンプルに考える。対象アイテムの直接のプロパティ値であるというメンタルモデル
- ジャパンサーチの二層モデル
- 使いやすさのために、
schema:creatorを用いて正規化値をその目的語とする(単純プロパティ) - 単純プロパティと構造化記述を併記し、いずれからも正規化値につながるようにする
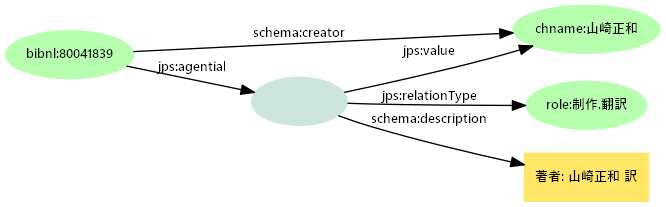
- 使いやすさのために、
-
- Web NDLAで標目形(優先ラベル)を
rdfs:labelとしても記述するのも同様の考え 
- Web NDLAで標目形(優先ラベル)を
(参考)Wikidataの記述モデル
- 直接プロパティと構造化プロパティの二層モデル
- 山崎正和の受賞(P166)の記述=賞名(文化勲章)に加え、受賞年2006と記述の来歴Wikipediaを付記

-
- 基本プロパティ(
p:P166)は受けた賞、時間、来歴の構造化ノードにリンク - 直接プロパティ(
wdt:P166)で受けた賞(文化勲章)のリソースにショートカット 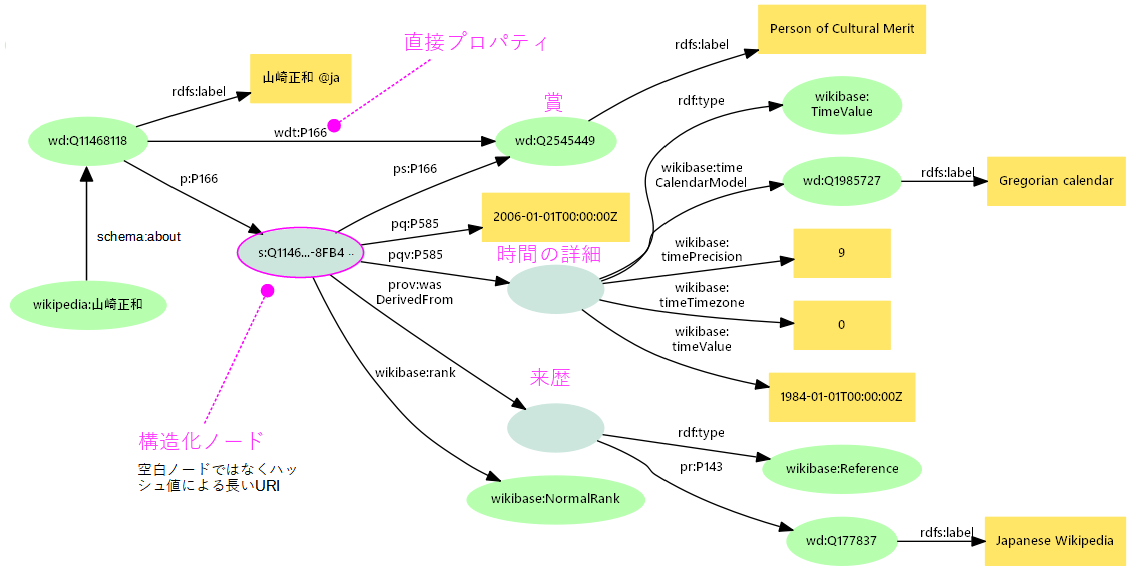
- 基本プロパティ(
全体・部分関係の記述
- シリーズ
- 全集、文庫など(seriesTitleで表現されているもの)
- 元の値がシリーズ名のみであってもURI化し、
schema:isPartOfを用いて関連付ける- 多くの場合、シリーズや文庫の名前は一貫性がある(ように見える。表記が不統一な場合もあるが柔軟に対応する)
- Webcat PlusはNDLの全国書誌とCiNiiのデータを統合しており、CiNii由来の上位シリーズIDを持つ
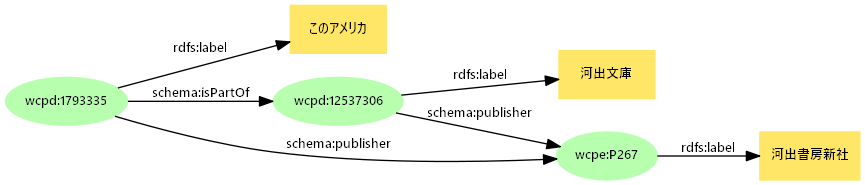
- コレクション
全体・部分関係の記述:構造化と二層モデルの導入
- 掲載誌情報の記述

- ①どの雑誌の②何巻何号の③何ページに掲載されているか
- 雑誌巻号②を一つの出版物とし、雑誌①とpartOfで関連付ける
- 記事を独立したアイテムとして②とpartOfで関連付け。さらに構造化して
selectorで掲載ページ
-
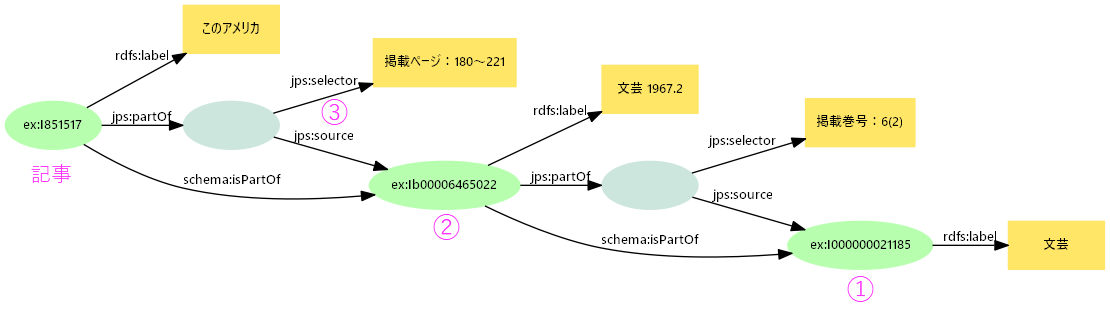
アイテムと作品:上演の記述モデル
- 演劇作品とその上演
- 早稲田演博演劇上演記録データベースは複数の上演アイテムが同一の作品を取り上げている
- 上演は日時・場所を持つイベント(公演)だが、作品の表現形と考えても良いかもしれない
- 上演と作品は
schema:workPerformedで関連付ける 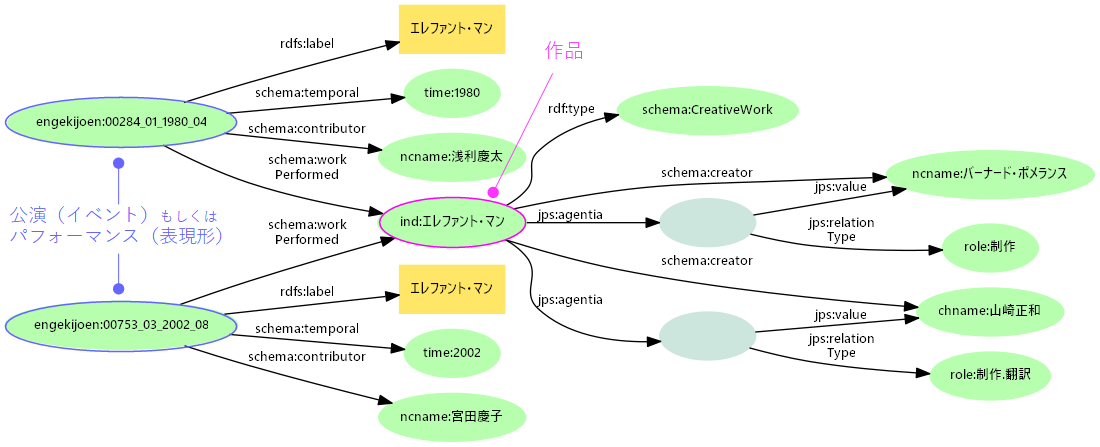
- 早稲田演博演劇上演記録データベースは複数の上演アイテムが同一の作品を取り上げている
- 芝居作品、上演、番付
- ARC番付ポータルはさらに番付(公演の宣伝刷り物)が複数の公演に結びつく
- 番付と上演は
schema:aboutで関連付け。さらに番付と作品もショートカットで結んでいる
(構想中)著作リストの作品と出版物
- 作品の掲載誌(初出)と書籍化
- 著作リストは「作品」ごとに掲載誌(初出)、書籍化などの出版物を記述する
- ここではFRBRの4階層ではなくBibframe型の3階層を用い、作品(Work)と出版物(Instance)を
schema:workExampleで関係づける 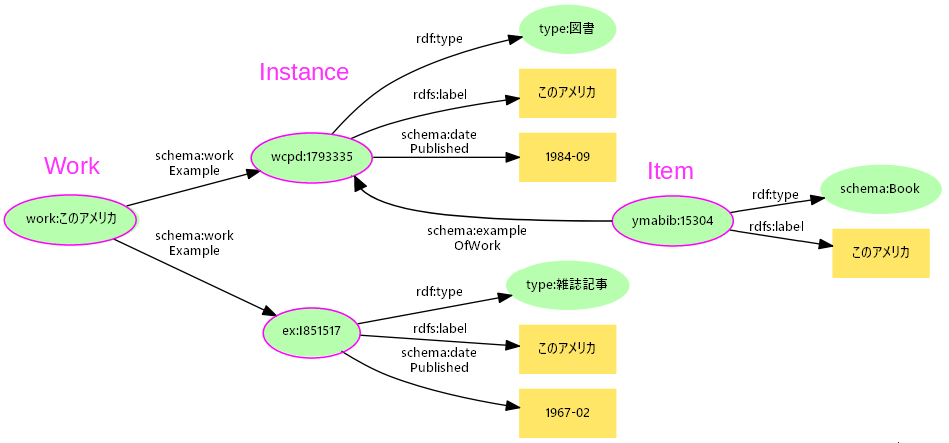
- さらに出版物の見本などの個別アイテム(Item)が蔵書にある場合は、これも
schema:workExampleで関連付ける- アーカイブのDBとしては、蔵書リストにおいてアイテム→出版物の
schema:exampleOfWorkとする方が扱いやすいかもしれない
- アーカイブのDBとしては、蔵書リストにおいてアイテム→出版物の
つながりを活かす
- データセット間の連携
- データセット連携によるタスク補完
- ひとつの目録で提供できる情報には限界が → 調べきれなかった情報を別のデータセットで調べる
- リンクされるLODとして外部からの利用促進
- データセット連携によるタスク補完
- リンクするデータによる探索
- セレンディピティ → 試してみるとそうお目にかかれるものではないが、LODクラウドを考えれば可能性はある
- IFLA LRMも3.3 User Tasks Definitionsの説明で重要としている
- むしろ同じポータル内でのリンクによるつながりで興味深い発見が
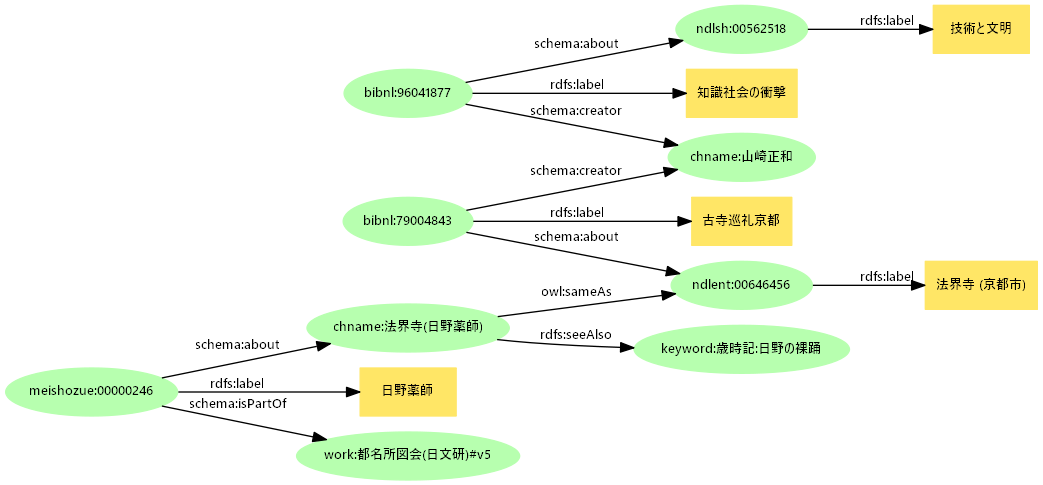
- セレンディピティ → 試してみるとそうお目にかかれるものではないが、LODクラウドを考えれば可能性はある
(構想中)注釈モデルによる引用からのリンク
- 引用を注釈モデルで記述する
- 山崎正和『このアメリカ』第九章に、小泉八雲『心』(平井呈一訳)からの引用がある
…早いはなしが、日本の國では、ごく普通につかっている日用品などでも、まず長持ちをさせようという考えで作られているものは、めったにない。たとえば、旅の泊りに着くたびに、切れては履きかえるあのわらじというもの。…
- Web Annotationモデルを応用して、注釈対象を書籍ページ、内容を引用文ノードとして表現
- 引用を介して作品から作品(著者から著者)への探索ができる
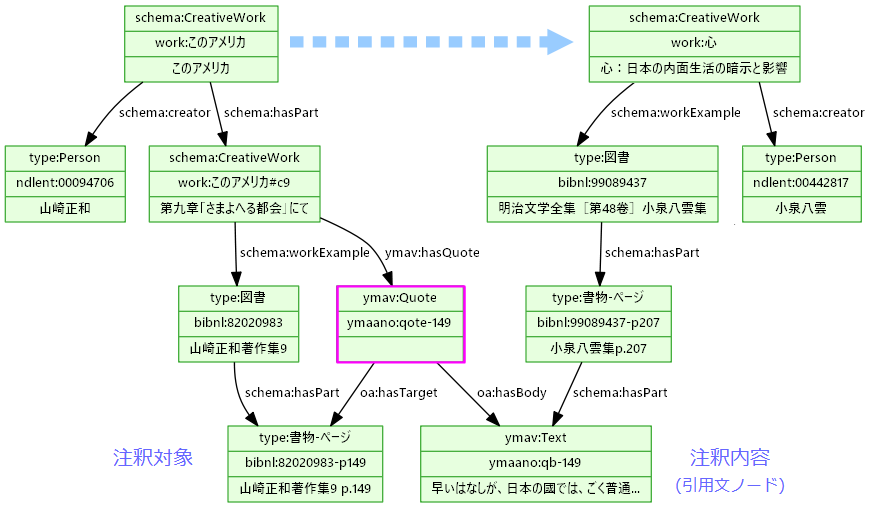
充実そして活性化
- 典拠の出典や関連を示す
- 典拠に収録する元となった文書などにリンクできれば、根拠を確かめることができる(典拠要素5.)
- 関連情報や背景をLODリンクで提供でき、典拠の理解・解像度が高まる(典拠要素3.および4.)
- 要素3.の識別に必要な情報は典拠が持つ方が使いやすいが、それ以上の追加情報はリンクとして利用者に提供
- IFRA LRMのNomenの属性にReference sourceが加えられていることにも対応する
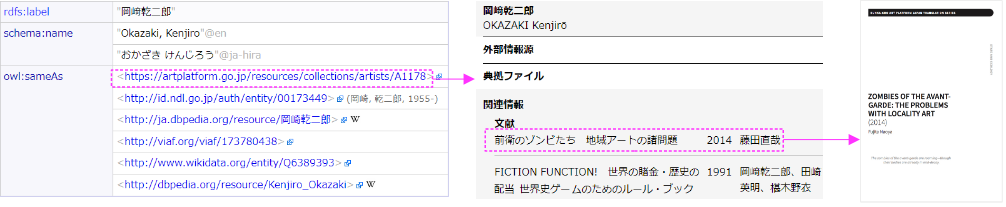
- さまざまな規模の典拠の連携
- 各組織の名前マスターテーブル → 外部典拠とのリンクで典拠として整備
- 地域、領域固有の名前を確実に典拠LOD化 → 得意分野を補完し合う典拠連携
- デジタルアーカイブとして個別品目を公開するだけでなく典拠もセットに
- 個別アイテムに「○○は江戸時代の~」とある詳細説明を典拠LODに。ぜひとも!
- 利用者としてのコンピュータ
- AIキュレーターによる展覧会企画では、不正確なメタデータに起因するおかしな選択やキャプションも
- 典拠とLODリンクを用いた明確なメタデータ
- たとえば人間の理解力に頼る責任表示ではなく適切な構造化とリンクする典拠