


文字って数字ですか?
前回は、1と0の2進数を8桁でひとまとめにし、「バイト」という基本単位として扱うということをお話ししました。1バイトは2の8乗すなわち256通りの情報を表現できるのでしたね。今回は、これを進めてコンピュータで文字を扱う方法について見ていくことにします。
*
コンピュータはもともと数値計算を目的にして作られたものですが、私たちは言葉(文字)を使ってアイデアを表現したり意志を伝えたりしているのですから、様々な情報を処理するにはどうしても文字も扱えるようにする必要があります。そこで、計算機にも扱いやすいように文字を数字に対応させ、ビット(1/0)の並びとして表現することが考えられました。
*
コンピュータは主としてアメリカで発達したので、まずは英文を表現することが必要です。この場合、アルファベット大小52文字、数字が10個、ほかに?#&*のような記号を合わせても100程度あれば間に合いそうですから、7ビット(7桁の1/0=128通り)を用い、これらを0〜127の数字に当てはめて表すことにしました。これがしばしばお目にかかるASCIIというもので、文字と数字の対応表です。8ビットじゃないのかって? そう、コンピュータでデータを扱う単位は8ビットなのですが、英文は7ビットで十分だったために、残る1ビットは使い方が定められなかったのです(このため、第8ビットはユーザーが独自の機能を割り当てたりして、のちに混乱を招く元になってしまいます)。今では8ビット目までを使った拡張ASCIIというコードで、独語や仏語でお目にかかるアクセント記号付きのアルファベットなどが定義されています。
*
このASCIIというコードをもう少し具体的に見てみましょう。
コード表を見ると、Aには65(10進数)という数字が割り当てられています(別にAが1であっても構わないのですが、過去の経緯などからこう決められました)。いったんAが決まると、残りの文字に対応する数字は、順番にB=66、C=67...と一つずつ大きくなるのが自然ですね。こうしておけば、文字列をアルファベット順に並べ替えるなどの操作が簡単にできるようになります。
では、小文字はどうするとよいでしょう。大文字のZは90になりますから、そこから続けてa=91、b=92...とするのが便利でしょうか? ASCIIでは、少し凝った方法を採用し、小文字を97から順に割り当てることにしました。その理由は、データを1と0のビット単位で見るとよくわかります。例えば大文字のAと小文字のaは
A=65=01000001
a=97=01100001
です。このビットの並びを比べると、6桁目(左から3番目)を除けば全く同じパターンですね。Bとb、Cとc...と進んでいっても、対応する数字が1ずつ大きくなるだけで6桁目以外が同じという関係は常に変わりません。つまり、大文字と小文字は1と0を1カ所入れ替えるだけで互いに変換できることになり、大小文字が混在する文字列の扱いが簡単になったのです。
*
日本語の場合は、8ビット(256通り)では明らかに不十分ですから、桁数を2倍にして16ビット(65,536通り)で文字を表現します。漢字の総数は4万7千字余りなので、16ビットあればすべてをコード化することも可能です。が、そこまでしても大半は滅多に使われない文字ですし、そのためにフォントを何万も作るのは現実的ではありません。そこでJIS(日本工業規格)がコンピュータで使用する日本語の文字の体系として約7000の漢字、かな、記号を定義しました。常用漢字が1945文字ですからそれに比べるとかなり広い範囲の文字を用意していると言えますね[1]。
*
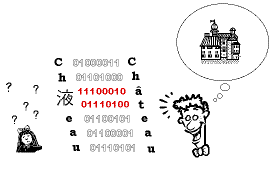 もともと1バイトの文字を扱うことしか考えられていなかったコンピュータで日本語のような2バイトの文字を扱うのは様々な困難が伴います。例えば、よくお目にかかるのが文字化けの問題。Cha^teauと書いたはずがCh液eauとなってしまうようなケースです。これは「液」という文字を構成する2つのバイトが、a^とtというアルファベット(拡張ASCII)の組み合わせと一致してしまうことが原因なのですが、これを完全に解決するには*、国際的な合意に基づいた新しい文字コードの制定を待つしかありません。実際にアルファベットを含む全ての文字を2バイトで定義し直したunicodeというコード体系が考えられており、次期OSのCoplandではこの体系が採用されるという話です。ようやく安心して日本語を使える時代が近づいてきたということでしょうか[2]。
もともと1バイトの文字を扱うことしか考えられていなかったコンピュータで日本語のような2バイトの文字を扱うのは様々な困難が伴います。例えば、よくお目にかかるのが文字化けの問題。Cha^teauと書いたはずがCh液eauとなってしまうようなケースです。これは「液」という文字を構成する2つのバイトが、a^とtというアルファベット(拡張ASCII)の組み合わせと一致してしまうことが原因なのですが、これを完全に解決するには*、国際的な合意に基づいた新しい文字コードの制定を待つしかありません。実際にアルファベットを含む全ての文字を2バイトで定義し直したunicodeというコード体系が考えられており、次期OSのCoplandではこの体系が採用されるという話です。ようやく安心して日本語を使える時代が近づいてきたということでしょうか[2]。
*
*一般にはその部分だけフォントを変えるなどの方法で対応します[3]。
*
(Beginners' Mac 1996/6号)
後記
日本語の文字コードに関しては複雑な問題が多いので、補足の説明を加えておきます。
- 1.JISで用意している文字
-
この文字の数が「かなり広い範囲」と言えるかどうかというのは、立場によって大きく異なります。第一水準漢字の3000文字足らずでも通常使われる文書の99%以上をカバーするという調査もあり、効率や実用を考える上では、7000字というのは十分多いのではないかということもできます。一方で文字文化という意味では、使用頻度が少ないからといって切り捨てるなどとんでもないという意見もあるでしょう。現実に、印刷関係ではこの7000字では不足するため、追加要求が出されてJISによる「補助漢字」5801字が別に定められています(実際にはほとんど実装されていない)。
- 2.Unicode
-
これについても単純に「ようやく安心して日本語を使える時代」とは言い切れず、様々な問題をはらんでいます。国際標準が必要であることは確かですが、Unicodeは、どちらかというとアメリカを中心とした一部の国の都合で規格化が進んでいる「業界標準」というべきもので、必ずしも現在のJISから「安心して」移行できるようにはなっていないのです。
- 3.多言語への対応
-
フォントによって言語(使用する文字セット)を切り替えるほか、JISでは国際規格に従ってエスケープシーケンスという特別な文字列で文字セットを切り替える方法を定めています。ただし、これはパソコンで使われるシフトJISでは適用できません。
これらに関する詳しい情報については「日本語と文字コード」のページを参照。