


URIとファイルディレクトリ
ごく簡単なHTMLの説明:ほかの文書、場所へのリンクで説明しているように、HTMLのハイパーリンクはURL (URI)という仕組みでリンク先を指定します。この記述方法は、ネットワーク上でのサーバーの指定方法と、サーバー内の特定のリソース(ファイルなど)の指定を組み合わせています。
URL : ウェブのアドレス指定方法
ウェブ上のリソースの「所在地」を示す方法としては、URL (Uniform Resource Locator) が用いられます(一般名称のURIについては本稿の最後で説明します)。これはお馴染みの
(例) http://www.kanzaki.com/docs/html/htminfo-uri.html
という形のものです。このhttp:で始まるURLは、次の3つの部分から構成されます:
- リソースを得るための手段の名前付け方法:http
- リソースを提供するホストマシンの名前:www.kanzaki.com
- リソース自身の名前(パス):/docs/html/htminfo-uri.html
1.の名前付け方法はスキーム (Scheme)と呼ばれ、「http」以外にもメールボックス(電子メールアドレス)を記述する「mailto」、ファイル転送に使われる「ftp」、ローカルディスクのファイルを意味する「file」などがあり、それぞれ2,3部分の記述方法が異なる場合もあります(たとえば、malitoスキームなら:に続くのはメールアドレスそのものです。記述方法はスキームごとに定められています)。
2.のホストマシンの名前の部分は、正式には責任者部 (Authority Component:3.の「パス」の整合性に責任を持つ主体)と呼ばれるもので、具体的には登録制のドメイン名を使ってインターネット上のマシンを特定します。ftpスキームでも同じようなドメイン名を使います。最初に「//」がついているのは、それがネットワーク上にあることを示します(file:///という形は、手元のファイルを示す場合にホスト名は不要なので、この部分が空白になっているわけです)。
3.のリソースのパス (Path)は、サーバー内部でのリソース(ファイル)の所在地を示すものです。PCでいえば、ディレクトリやフォルダの名前を含んだファイルの名前に相当します。
これらの機能の組み合わせによって、ウェブ上のあらゆるリソースの所在地を重複なく特定することができ、かつそのリソースを取得するための手段も示すことができます(※)。スキームの部分は、新しい技術が登場すれば対応するものを追加定義することができるので、将来にわたってURLによってあらゆるリソースを指定できることになるのです(ただし、安易に新スキームを提案・導入するべきではありません)。
- URLについては雑誌『NetFan』1997年1月号に掲載した解説記事も参照
※厳密に言うと、URLで示されるリソースは必ずしもネットワーク経由で取得できるとは限らないのですが、多くのソフトウェアは、このスキームによって、リソースにアクセスする(を試みる)ための手段を判別します。
ディスクのディレクトリ構造とファイルパス
ほとんどのコンピュータは、ファイルを「ディレクトリ」「フォルダ」という単位で階層構造にして管理しています。これは、ファイルの数が多くなると、一括管理では手に負えなくなってしまうためで、それぞれのルールや慣習に基づいて、大きなグループのディレクトリ、その子ディレクトリ、孫ディレクトリというかたちでファイルを分類保管します。このツリー構造の一番親に当たるディレクトリを「ルートディレクトリ」と呼びます。
たとえば、Windowsにおいては、システム関連のファイルは「Windows」というフォルダに、自分で作成するファイルは「My Documents」というフォルダに分類されます。両者が入り混じってしまっては、とても扱いがやっかいですから、これは合理的な分類といえます。更に「My Documents」の中には、自分の作業に応じて「business」とか「private」などの子フォルダ(サブフォルダ)を設け、必要に応じてさらにその中にもサブフォルダをつくってファイルを管理していることでしょう。
(root)-----Windows
| |--system
| ...
|--My documents
| |--private
| | ...
| |--business
| | |--clients.txt
| | |--schedule.txt
....
ファイルのパス (path=ファイルへの経路)とは、ルートディレクトリから個々のファイルに至るまでの、すべてのフォルダ名を列挙してファイル名を示すもので、コンピュータ内のファイルの所在地を、ほかのファイルと混同することなく、確実に指定できます。たとえば、うえの例の「business」フォルダの中に「clients.txt」というファイルを保管していれば、このファイルへのパスは
(例)\My Documents\business\clients.txt
と書き表すことができます。ここで、フォルダの名前を区切るのに使われる「\」という文字は、ファイルシステムによって異なり、Windowsなら「\」、Macintoshなら「:」、UNIXでは「/」という具合です。
〔補足〕
インターネットはUNIXをベースに発展してきたので、URL でのファイルパスの部分は、「/」で区切ります。最初の例に挙げた「/docs/html/htminfo-uri.html」は、
(root)-----
| ...
|--docs
| |--html
| | |--htminfo-uri.html
....
〔以上補足〕
というファイルを指しています。
ウェブサイトを構築するとき、(特に個人の場合は)最初はファイルが少ないので、すべてのファイルをルートディレクトリに置いた構成にしてしまうことがよくあります。サイトが発展してファイルが増えてくると、ルートディレクトリがぐちゃぐちゃになってしまうため、後でディレクトリの構成を変更することになります。そうすると、サイト内のファイルのリンクを書き直す羽目になりますし、外部からリンクしてもらっている場合、それらのリンクが切れてしまうことになります。ちょっと大げさと思っても、最初からきちんとしたディレクトリ構造を用意してウェブサイトを作っていくようにしたいものです。
- リンク切れを起こさないための設計については「クールなURIは変わらない」を参照
相対パスによる指定
URLはhttpからはじめてホスト名、パスを全て記述する絶対URLと、一部分だけを指定する相対URLがあります。相対URLの場合は、ブラウザが現在の基準ディレクトリURL(相対URLが記述されているファイルがあるディレクトリのURL)を補って解釈してくれます。
たとえば、http://www.kanzaki.com/bass/index.htmlで示されるファイルの中に <a href="giant.html"> というリンクがあると、ブラウザはhttp://www.kanzaki.com/bass/を基準ディレクトリURLと考え、リンク先のURLをhttp://www.kanzaki.com/bass/giant.html と解釈してくれるのです。
相対URLを用いると、ファイルの相対的な位置関係が同じであれば、サーバーを変更してもリンクを書き直す必要がないというメリットがあります。ローカルディスクでファイルを編集して、プロバイダのサーバーにアップロードするような場合に便利です。
相対URLの書き方
以下の例では、ファイル名と区別するためにディレクトリ名は[ ]で囲んで示しますが、実際の名前は[ ]のないものと考えてください。
[fruit]
|--[apple]
| |
| |--macintosh.html
| |--mutsu.html
|
|--[orange]
| |
| |--natsumikan.html
|
|--grape.html
|--peach.html
上図のファイルmacintosh.htmlから同じ [apple] ディレクトリ(フォルダ)にあるファイルmutsu.htmlにリンクするには
(例)<a href="mutsu.html">
と直接ファイル名を記述しますが、一つ上の階層のディレクトリ [fruit] にあるファイルgrape.htmlへのリンクの場合は
(例)<a href="../grape.html">
のように指定します(2つのピリオド「 .. 」は親ディレクトリを表します)。また、同じレベルの隣のディレクトリである [orange] のnatsumikan.htmlへのリンクなら
(例)<a href="../orange/natsumikan.html">
となります。さらに、
(例)<a href="/orange/natsumikan.html">
という形で、「/」から書き始めたURLを用いると、サーバーのルートに対する相対URLとして扱われます(この場合、[orange] がサーバーの第1階層のディレクトリという意味)。様々な階層のファイルから、ホームページ(/index.html)にリンクするような場合にうまく使うことができます。
URLで使用する文字
URLで使用できる文字は、基本的にASCII文字(アルファベットと数字と記号)に限定されます。日本語をファイル名に用いると、いろいろとトラブルのもとになるので、ファイル名はアルファベットを用いるようにしましょう。
ファイルパスの部分は、サーバーがUNIXの場合、大文字と小文字を区別します。WindowsやMacintoshはこれを区別しないため、ローカルディスクで作成したファイルでリンクを確認したのに、プロバイダのサーバにアップロードしたら「File Not Found」になってしまうというエラーが頻発しています。特にWindowsの場合、表示の設定によっては「エクスプローラ」で確認できるファイル名の大文字・小文字が実際のデータと異なっていることがあるので、注意が必要です。
また、URLにはスペースや&など、いくつか使用できない文字があります。スペースはWindowsでもMacintoshでもファイル名に許されているので、使ってしまうことがありますが、危険なのでやめておきましょう。どうしてもスペースを含める必要がある場合は、スペースを「%20」で置き換えます。つまり「My%20Documents」という具合です。
話を簡単にするために、WWWで公開するためのファイル名は、小文字のアルファベットと数字のみで付け、補助的に「-」「_」(及びファイル拡張子を区切る「.」)を使うと考えておくと良いでしょう。
※URLに日本語などを用いるための国際化に関しては、IRIという規格がRFC3987で定められています。。少々ややこしい話ですが、当サイトのメモ「国際化識別子IRIがRFC3987に」において簡単に触れています。
URIとURL
ここまで URL という用語を用いて説明してきましたが、WWWに関する文書を読むと、最近はURI (Uniform Resource Identifiers [注]) という言葉が使われていて、ちょっと混乱しそうです。あまり気にしなくてもいいのですが、実際に混乱もあるので、2001年9月にW3CノートURIs, URLs, and URNs: Clarifications and Recommendations 1.0が公開され、「古典的な説明」と「現在の見解」にわけて考え方が示されています(2002年8月にはRFC3305としても公開されました)。
現在の見解
ウェブ上でリソースを識別する手段はURIで、その中にhttp:, ftp:, urn:などのスキームが存在します(URIの中にURLとURNという2つの大きな区分が存在し、URLの中にhttp:などが含まれるという階層構造ではありません)。
URLはURIのうち、「主たるアクセス手段」を識別の手法とするものを指す「(有用ではあるけれども)非公式な」概念です。また、URN (Uniform Resource Name) はurn:という1つのスキームで、それに続くNID (Namespace ID) とセットでURN名前空間を定義します。
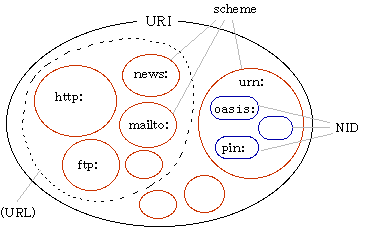
古典的な説明
従来は、URI = URL + URNと説明され、必要に応じてURL, URN以外の新しい区分が追加され得る(提案された例としてはURC)とされてきました。URLの場合は、Locator(場所指定)という名前が示すように、この 「リソース指定」の部分はネットワーク上のアドレスになります。これに対し、名前でリソースを識別する方法がURNということになります。W3Cのサイトでは、次のような概念を示す図と説明が記載されていました。
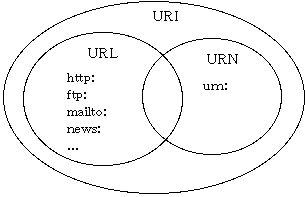
- URLは「アドレス」などの具体的なアクセス手段によってリソースを識別する方法。
- URNは「名前」という普遍的な属性でリソースを識別する方法で、リソースが移動したり消失しても有効なもの。
- URLのうち、リソースが移動しても普遍的に識別できることが組織などによって保証されているもの(パーマネントアドレス)は、URLでありかつURNでもある。
URIの意味するところ
RFC 3986の"1.1 Overview of URI"では、U,R,Iについてそれぞれ次のように定義しています。
- Uniform
- 統一した書式を定めることで、いろいろな種類のリソース指定方法を同じ文脈で区別することなく扱えるようにし(例えばどんなURIも <a href=...> において自由に記述できる)、また新しい手法(スキーム)の導入を容易にします。
- Resource
- リソースについては特に制約を設けず、「URIで識別可能なものなら何でも」と定義されています。WWWではファイルが一般的な例ですが、人、会社、本、東京のお天気情報など、他と区別ができるものはみんなリソースです。リソースは単一の個体である必要はなく、「○○図書館の本」のような集合体もリソースとして捉えることができます。さらに、“音楽”のような抽象的な概念や“親”といった関係も、リソースとして扱うことができます。
- Identifier
- 「識別子」と訳されますが、定義としては「対象をその識別システム内の他のあらゆるものから区別するために必要な情報」となっています。(RFC 3986では、RFC 2396よりもIdentifierの定義が詳しくなり、識別子は必ずしも対象のアイデンティティを示すとは限らないこと、また識別子は対象にアクセスする手段とは限らないことが注記されました。)
いろいろなスキーム
じゃあhttp:やftp:などのいわゆるURL 以外にどんな URI が使われているの? 公式なURIのスキームは、IANAに登録されているものとして30ほどあります(Uniform Resource Identifier (URI) SCHEMESで参照できます)。良く知られているものとしては、携帯電話用のウェブで使われるtel:もあげられるでしょう(インチキだと思っている人がいるかも知れませんが、tel:そのものは正式に登録されたURIのスキームです)。これ以外にも、登録はされていないものの概要を説明する文書が公開されている「公開非登録スキーム」と呼ばれるものがあって、たとえばアンカーでスクリプトを起動させるために使われるjavascript:なんてものはよく見かけます。これらを含む公開スキームは、ダン・コノリーによるAn Index of WWW Addressing Schemesに80強がリストアップされています。
登録も公開もされていない「プライベート・スキーム」は、ソフト会社の独自仕様に基づくものがいろいろあります。よく使われるものとしては、たとえばobject要素のclassid属性で用いられるclsid:があります。
(例)<object classid="clsid:166B1BCA-3F9C-11CF-8075-444553540000" ... >
オブジェクトを実行するコード(プラグインやアプレットなど)の「所在地」を示すものですが、classid属性の値はDTDで%URI;とされているので、これは(いちおう)URIということになります。
また、ISBNコードを使って特定の書籍を「識別する」ような使い方を考えることができます。
(例)urn:isbn:4-939039-02-1
書籍には「場所」という概念は結びつかないので、この場合はURNとしてISBNコードが使われているわけです(ISBNは公式に登録されたURNの名前空間となりました。URNについては、当サイトのURNについての簡単な説明を参照してください)。
※スキームがたくさんあるのは、その役割の基本的な理解を欠いたまま粗製濫造されたという側面があります。当サイトのメモ「過剰なURIスキームは有害である」を参照してください。
参考:
- RFC 3986: Uniform Resource Identifiers (URI): Generic Syntax
- Web Naming and Addressing Overview (URIs, URLs, ...) at W3C
〔補足〕*以前はURIはUniversal Resource Identifiersの略とされていました(例えばRFC 1630)が、今はURLとの整合性をとるためか、Uniform Resource Identifiersということになっています。ただし、しばしば両方が混在して用いられています。