


文字列を自在に、軽やかに
HyperCardはユーザーのイマジネーションで幅広い表現や実用スタックを生み出せる柔軟な環境だ。XCMDで機能を拡張すればその可能性は更に広がる。10年に及ぶ歴史が育んだ定番ツールの使い方を研究し、HyperWorldを味わい尽くそう。
XCMDでハイパーカードをチューンナップ
ハイパーカードはマッキントッシュ上でユーザーがカスタムアプリケーションを作るのにもっとも適した環境の一つである。
まず、HyperTalkは比較的習得が簡単で、しかもかなり豊富な命令を備えていること。これはインタープリタ言語だから、アイデアを試したり改良が気軽にできる。さらに、最も手間のかかるユーザーインターフェイス部分が、フィールドやボタンの配置だけで済んでしまう。多くのツールや参考書籍が広く流通していることも自作派にとっては心強い。
その一方で、簡単であることの代償として、HyperTalkはスピードや機能の面で制約を受けることになった。それを補う手段として提供されたのが、外部拡張命令つまりXCMDである。これはMacOSのほぼ全ての機能を使うことができ、かつ非常に高速に実行される。この仕組みによって、ハイパーカードの可能性は大きく広がったのだ。
幸いなことに、ハイパーカードの10年に及ぶ歴史は多彩な公開XCMDを育んできた。プグラミング言語を用いて自作しなくても、オンラインライブラリを探せばたいていの必要は満たすことができる。
その中でも、種類・機能ともに最も豊富にそろっているのが、フランスのフレデリック・リナルディ氏によるXCMDのコレクションだ。その数はゆうに100を越え、欲しいツールはほとんどこの中で見つかるといっても過言ではない。しかも、それぞれの機能はきめ細かいオプションを提供していて非常に強力である。このセットさえあれば、ハイパーカードで何でもできてしまうという魔法の玉手箱のようなものだ。
このツールをより多くの人が利用できるようにするため、リナルディ氏の許可を得てコレクションをCD-ROMで提供し、主要なXCMDの解説と応用例を紹介していくことにした。多彩なツールを6つのグループに分けてお届けする。第1回はテキスト処理のツール集だ。
文字列データを処理する
いまコンピュータ上でもっとも汎用性の高いデータ形式はテキストである。文章はもちろんのこと、数値データも日付データも、この形式にしておけばあとから表計算やデータベースに取りこんで処理することができる。それに何といっても機種を問わないところがありがたい。インターネット上の情報も基本はテキストだ。
HyperTalkは文字列の扱いに長けていて、そのための様々な命令を持っている。データを外部のテキストファイルに保存しておき、必要に応じてその内容を参照したり、あるいは扱いやすくするために形式を変換したりするのはハイパーカードの得意業だ。しかし、データの量が大きくなると、だんだんHyperTalkのスピードの限界が目につき始める。例えば、エディタなら普通に備えている置換命令を行うためには、リスト1のような形で、繰り返し命令を延々と実行しなければならない。この方法だと、例えばUNIXスタイルのLFによる改行をMacintoshのCRに変換するという基本的な操作でも、わずか250行の単純なテキストを処理するのに1分以上かかったりしてしまう。こうした文字列処理を高速に、かつ手際よくこなしてくれるのが今回取り上げる文字列処理関数群である。
リナルディ氏のコレクション中これに該当する関数はいくつかあるが、ここではもっとも強力で応用範囲の広い
- FullFind
- FullReplace
- ExtractItems
の3つを取り上げて解説しよう。
FullFind
データのなかから特定の文字列を探し出す関数である。基本的な使い方は
get FullFind(str,pattern)
のような形で、結果はpatternが見つかった位置のbyte, line, byte in the line, item in the lineが順番にアイテムとして返される。byteはstrの先頭から数えたバイト数、byte in the lineはpatternを含む行の先頭から数えたバイト数だ(*注1)。見つからなかった場合は空白が返される。
ここで便利なのは2番目のアイテムとして得られる行番号だろう。特定の文字を含む行全体を抜き出そうという場合、HyperTalkでは面倒な方法が必要だった(*注2)。それがXFCNを用いると
get line (item 2 of FullFind(str,pattern)) of str
とするだけで目的の行を抜き出すことができる。住所録を行単位のテキストデータベースとして持っているときなど、重宝すること間違いない。
このXFCNは次のような強力なオプションを備えている。
FullFind(<container>,<pattern>[,<exact>[,<all>[,<case>[,<start>[,<item(s)>]]]])
- exact
検索パターンを完全な単語として扱うかどうか。FALSEにするとfindというパターンで検索したときにfinderのような派生語も合わせて検索できる。省略した場合はTRUEとみなされる。
- all
TRUEを指定すると、コンテナ中のパターンを全て拾い上げて列挙する。FALSEの時は最初に見つかったパターンの位置のみを返す。省略値はFALSE。
- case
大文字小文字を区別するかどうか。TRUEの場合に区別する。省略値はFALSE(区別しない)。
- start
文字列中、パターンの検索を開始するバイト位置。指定した数字の次のバイトから検索する。省略値は0(最初から)。
- item(s)
ここにアイテムを示す数字のリストを入れておくと、各行の指定したアイテムについてのみパターンを検索する。省略すると全体を検索。
例えばallオプションをつかうと、住所録から豊島という名前の人を全部リストアップするというようなことが簡単にできる。このとき、XFCNから返される結果のアイテムリストは、該当1件につき1行になっている。5件見つかったら5行の結果になるわけだ。また、item(s)で検索する範囲を限定すれば“豊島区在住の人”を豊島さんとして検索することもない。リスト2のようなスクリプトがあれば、電話番号を調べるためだけにわざわざデータベースソフトを立ちあげなくてもすむ(*注3)。
FullReplace
先ほどのFullFindが検索専門なのに対し、こちらは置換を行うXFCNである。基本形は
put FullReplace(data, searchStr, replaceStr) into data
というものだ。デフォルトで全置換を行うので、これだけでリスト1と同じ働きをしてくれる。
6行のスクリプトが1行で書けるというだけではなく、スピードも断然速い。先ほどのLFをCRで置き換える例で見れば、同じ処理をこちらはわずか1/10秒でこなしてしまう。1000倍近いスピードということになるわけだ。データが大きくなればなるほど、このメリットは大きい。これくらいの能力があれば、簡単な業務用アプリケーションにも応用可能だろう。
こちらにもオプションはいろいろ用意されている。
FullReplace (<input>,<search pattern>[,<replace pattern>[,<all>[,<offset>]]])
- all
全置換を行うかどうかを指定する。FullFindとは逆に、省略値はTRUEとなっている。
- offset
FullFindのStartオプションと同じく検索を開始するバイト位置を示す。ただしこちらはFullFindと異なり、指定した値が開始位置になるので注意が必要。省略値は1、つまり最初からとなっている。
FullReplaceはFullFindのようなExact,Caseオプションはなく、常に単語の一部も含み、大小文字は区別しない。
このXFCNは、あるテキストを一定の規則に従って別の形式に変換するフィルタを作成するときに非常に強力なツールになる。先ほどのような改行コードの変換や、CSV形式のデータをTAB区切りデータに変換するなど、こういうちょっとした変更を行いたいケースというのは日常たくさん遭遇するはずだ。
ExtractItems
これはカンマやタブで区切られたアイテムを持つ複数行のリストから、特定のアイテム(列)を抽出してくれる便利なツールである。使い方は、例えば2番目と4番目のアイテムをぬきだすなら
put ExtractItems(data,2,4) into newList
のようなシンプルな形。同じことをHyperTalkで行うとリスト3のようになって、時間も20倍以上かかってしまう。多くのフィールドをもつテキストデータベースから必要に応じて情報をコンパクトな形で利用する場合に役に立つ。たとえば住所録データから氏名と電話番号だけのリストを作るようなケースだ。FullFind()とあわせて使うと、かなり実用的なデータベーススタックをつくることができる(画面1)。
HTMLへの変換ツール
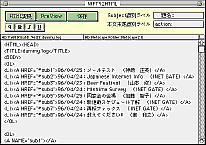 これらのXFCNを組み合わせると、あるテキストファイルを別の形式に変換する「フィルタ」と呼ばれるツールを手際よく作成できる。いろいろな応用が考えられるが、ここでは面白いサンプルとして、ComNiftyで通信したログファイルから(特定の)メールを取りだし、HTMLファイルに加工するツールを考えて見よう。メーリングリストのログをまとめてホームページで公開するときなどに便利である。
これらのXFCNを組み合わせると、あるテキストファイルを別の形式に変換する「フィルタ」と呼ばれるツールを手際よく作成できる。いろいろな応用が考えられるが、ここでは面白いサンプルとして、ComNiftyで通信したログファイルから(特定の)メールを取りだし、HTMLファイルに加工するツールを考えて見よう。メーリングリストのログをまとめてホームページで公開するときなどに便利である。
リスト4を見てみよう。
3行目でNIFTYのメール中のタイトル(サブジェクト)を見分けるキー文字列を定義し、4行目でFullFindを使ってこの文字列を調べあげる。5行目はメール本文の最後をやはりFullFindで調べる命令だ。ここではComNiftyの自動運転を想定して"action:"というプロンプトを目印にしているが、それぞれの環境に応じて置き換えればよい。
FullFindの第4引数(all)をTRUEにして該当するパターンを全て列挙しているから、変数mailTopの行数はメールの件数に等しいことになる。そこで6〜14行のループによって、全てのメールについてHTMLタグを加える処理が行われるわけだ。
7、8行で各メールの最初と最後の位置を取得する。9行目ではメールのタイトルを取り出しているが、ここでは合わせて「題名:」というような不要なラベルをFullReplaceで取り除いておく。10行目と13行目は長い命令で読みにくいが、HTMLのアンカータグを設定している部分だ。
ここで11〜13行に使っているFullReplaceに注意して欲しい。これは、HTMLテキスト中に使えない文字(<と>)をしかるべき表現に置き換えたり、明示的に<br>で改行するというような独特の書式を一括して処理している。こういうところはHyperTalkのみで片づけようとするとrepeat文の嵐となって、とんでもなく複雑になってしまうだろう。XCMDの威力が発揮されている好例である。
最後に15行目でリストを構成するタグを加えて、HTMLの本体が完成した。あとはこの関数(makeHTML)を呼び出したほうで、<head><title>などのタグを整えて保存するという手はずだ(画面2,3)。簡単なものだがこれを応用することで自在にHTML変換ツールを作成することが出来る。XCMDを使って効率よく文字列を処理するヒントになっただろうか。
最後に、リナルディ氏のXCMDのうちテキストを処理するものを一覧にしてまとめておこう。
| ExtractItems | 複数行のリストから、特定のアイテム(列)を抽出してくれる | ExtractItems(<text>,<item nb>[ノ<item nb>] [,<item sep>[,<line sep>]]) |
|---|---|---|
| FullFind | データのなかから特定の文字列を探し出す | FullFind(<container>,<pattern> [,<exact>[,<all>[,<case>[,<start> [,<item(s)>]]]]) |
| FullReplace | 文字列の置換 | FullReplace(<input>,<search pattern> [,<replace pattern>[,<all>[,<offset>]]]) |
| FullSort | 多機能なソート。特に<sort list>オプションを用いて複数のフィールドを連動させる機能がユニーク。 | FullSort(<text>[,"l=<sep>"][,"i=<sep>"] [,"t=a|n|d|i|u"][,"d=a|d|r|l"][,"c=char x|word x|item x[ to y]"] [,<sort list>]) |
| ReplaceCharSet | 複数の文字を一度に別の文字セットに変換する | ReplaceCharSet(<text>,<original set>, <substitution set>) |
注
*注1
英文の場合はcharもbyteも同じことだが、HyperTalkのoffset関数などは2バイト文字も1文字とみなして数えるので、日本語文字列でパターンを探した結果はFullFindとは異なってくる。
*注2
repeatを使って1行ずつ調べるか、offsetで文字列の位置を調べた上でその前にある改行の数を調べるなどの方法になる。
*注3
ファイルから特定の文字列を含む行だけを取り出すなら田中求之氏のMtGrepのように更に手軽なXCMDもある。
リスト
リスト1
--文字列全体をdata、検索語句をsearchStr、置換語句をreplaceStrとする put number of chars of searchStr into n repeat get offset(searchStr, data) if it is 0 then exit repeat put replaceStr into char it to (it + n-1) of data end repeat
リスト2
-- 氏名は1番目のアイテムになっているとすると -- 全ての豊島さんを拾い出すには put FullFind(AddressData,"豊島",FALSE,TRUE,FLASE,0,1) into res repeat with i=1 to number of lines of res put line (item 2 of line i of res) of AddressData & return after myText end repeat put myText into fld "Display"
リスト3
-- dataの各行から2番目と4番目のアイテムを抜き出す repeat with i=1 to number of lines of data get line i of data put item 2 of it & "," & item 4 of it & "," & return after newList end repeat
リスト4
-- strとして与えられるログファイルの中身からメール部分を取り出し
-- HTMLのリストの形式に変換する関数
1: function makeHTML str
2: put QUOTE into Q
3: put " 題名:" into topLabel
4: put FullFind(str,topLabel,FALSE,TRUE) into mailTop
5: put FullFind(str,"action:",FALSE,TRUE) into mailEnd
6: repeat with i=1 to number of lines of mailTop
7: put item 2 of line i of mailTop into s
8: put item 2 of line i of mailEnd into e
9: put FullReplace(line s of str,topLabel,"") into title
10: put "<li><a href=" & q & "#sub" & i & q & ">" &
title & "</a>" & return after titleList
11: put FullReplace(line s+1 to e-1 of str, ">", ">") into myBody
12: put FullReplace(myBody, "<", "<") into myBody
13: put "& lt;a name=" & q & "sub" & i & q & "></a>" & return &
"<dt><b>" & title & "</b>" & return & "<dd>"
& FullReplace(myBody, return, "<br>" & return) & return after body
14: end repeat
15: put "<ol>" & return & titleList & "</ol>" & return & return &
"<dl>" & return & body & "</dl>" & return into res
16: return res
17: end makeHTML
*13行目で"<dt><b>"としているところは、雑誌掲載時には"<dt><h3>"のようになっていたが、もちろんこんなところに<h3>タグを用いることはできないので修正した。
(MacUser Japan, July 1996)