ジャパンサーチ利活用スキーマの設計と応用
- ジャパンサーチ メタデータの構築
- 分析と概念モデル:FY2017
- マッピング開発からベータ版公開:FY2018
- 連携フォーマットと利活用スキーマ
- 利活用スキーマへの変換の流れ
- 利活用スキーマのインターフェイス
- 利活用スキーマの設計
- 利用者タスクによるメタデータ分析
- 共通記述情報とソース情報の分離
- 共通記述情報の基本項目
- 名称とラベル
- 複レイヤ構造と語彙の選定
- レイヤⅠ:シンプル記述
- レイヤⅡ:構造化記述
- 構造化記述:注釈あるいはプロパティグラフ
- 正規化値とLOD
- 汎用共通項目
- アクセス情報とメディアオブジェクト
- 利活用スキーマRDFの探索と応用
- いつ:時間正規化と範囲検索
- どこ:位置情報の利用
- なに:グラフによる探索
- さらにグラフ探索
- だれ:正規化と統合クエリ
- ジャパンサーチ内の新しい関係を見出す
- 注釈によるユーザ発信情報
- データとしての利活用スキーマRDF
- スキーマ(モデル)自身の活用
- 課題と展望
- ベータ版公開から5ヶ月
- 正規化の課題
- クラス定義のあり方
- 活用できるポータルへ
- 参照先
利活用スキーマへの変換の流れ
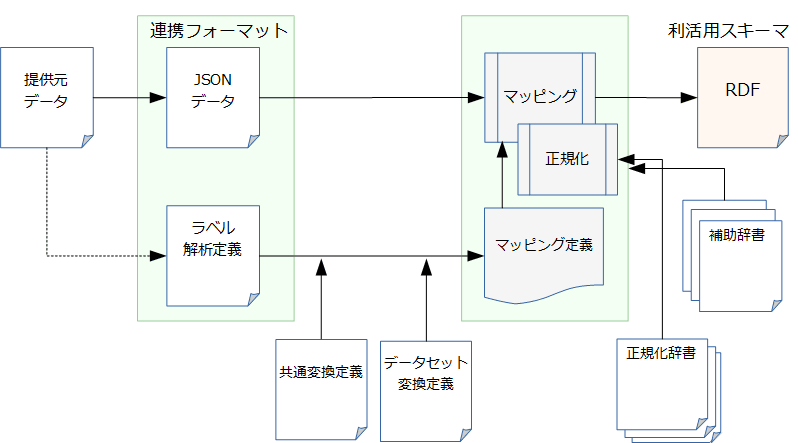
- 利活用スキーマRDF生成のワークフロー
- 連携フォーマットの共通項目に対応する共通変換定義と、データセットごとの個別変換定義を組合せ、マッピング定義を準備
- マッピングツールは辞書を用いて値を正規化する正規化モジュールを呼び出しながら、各アイテムをRDFに変換
共通記述情報とソース情報の分離
- 共通記述+アクセス・ソース情報の構造
- 分野を問わない、発見~選択タスクに重要な共通記述を設定
- 取得タスクのための、アクセス情報を集約
- ソースを共通記述から分離し、来歴の明示とともに元データ取得も可能に
- 共通記述は無理に100%の変換を目指さず、共通化しないものはソースに任せる(導入句付き
schema:descriptionでも)
- 共通記述は無理に100%の変換を目指さず、共通化しないものはソースに任せる(導入句付き
- Europeanaモデル(EDM)とも対応する共通記述とアクセス・ソース情報の分離
- 共通記述及びソースデータ(sourceData)が
ore:Proxy、アクセス情報がore:Aggregationに相当 - 各
ore:Proxyはそれぞれの視点でのメタデータを記述
- 共通記述及びソースデータ(sourceData)が
レイヤⅠ:シンプル記述
- Schema.orgによる分かりやすい記述
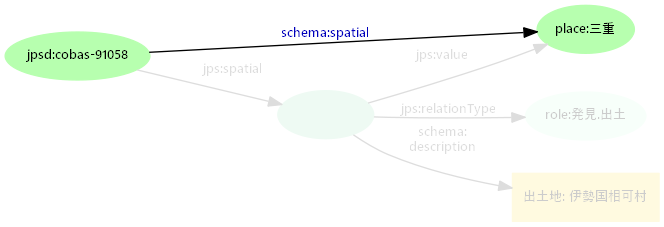
- 基本的なパターンで検索でき、モデルに関する特別な予備知識を求めない
SELECT * WHERE {?sschema:spatial place:三重}- Schema.orgは世界的に広く利用され、特別な説明なしに通じる
- RDFに親しみのないウェブ開発者も利用しやすい
- 値も正規化し、異なる表記も一貫して検索できるようにする
レイヤⅡ:構造化記述
- シンプル記述と対になる構造化ノード
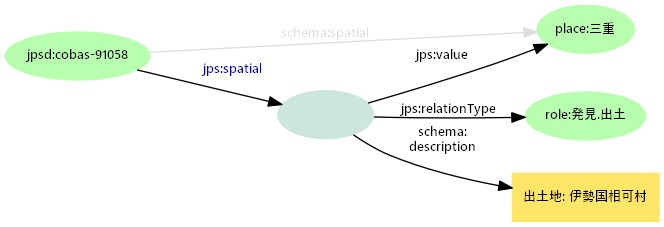
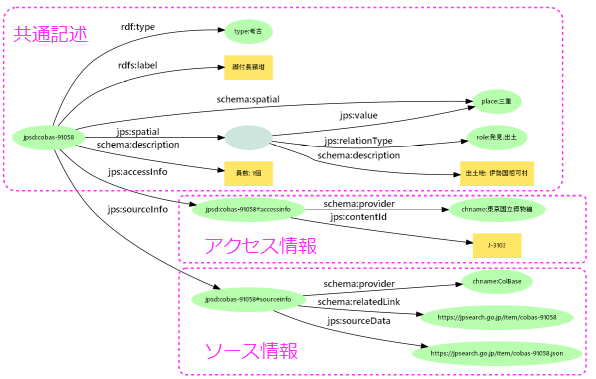
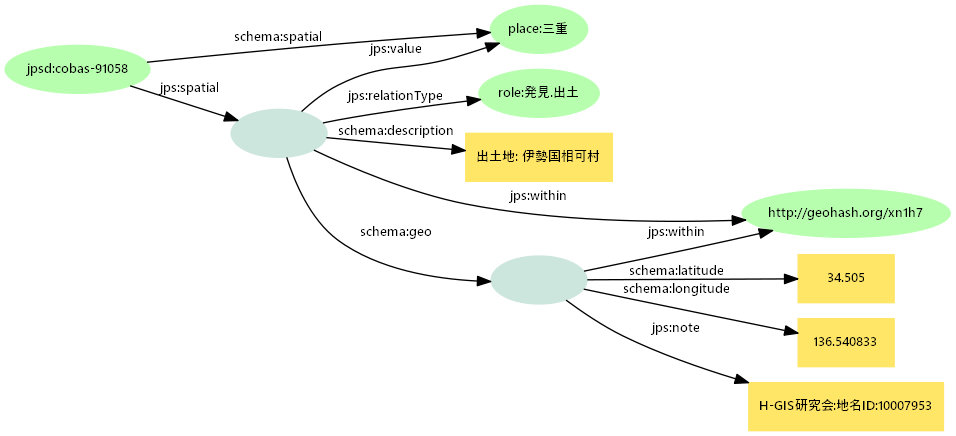
- 構造化記述プロパティ+関係タイプ(作者、訳者、制作地、出土地)
- 元データの項目名(出土地)の詳細は関係タイプで記述=元項目名の保持&文脈付与
- 関係タイプは制作、公開、発見、取得、記録、出演、内容、支援、関連の大区分
- さらに
role:発見.出土という形で小区分を設け、大区分と関連付ける。小区分は変換時に動的生成も
- 変換元データの保存(住所→都道府県のような正規化で失われる情報)や処理に関する注記
- 元データはソース情報でも辿れるが、利用時のスムーズな確認は重要
- さらに緯度経度、時代などの付加価値情報を追加できる
- 伊勢国相可村発掘「脚付長頚坩」の場合:緯度経度とその判定に用いた辞書を注記
jps:valueプロパティでシンプル記述と同じ正規化値に関連付ける
構造化記述:注釈あるいはプロパティグラフ
- シンプル記述の関係への説明的注釈
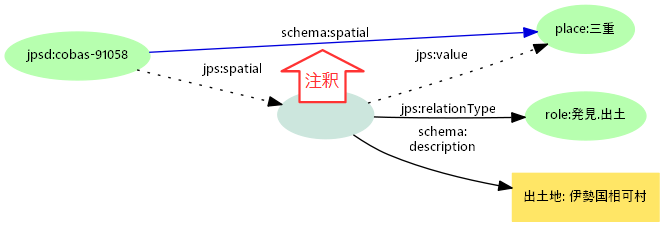
- 構造化ノードはシンプル記述の説明もしくは注釈と考えることができる
- プロパティグラフの関係プロパティと捉えてもよい
- プロパティグラフはノード(円)、関係(矢印)がそれぞれプロパティ(キー:値の組;RDFでいうプロパティとは異なる)を持つことができる
- 関係はタイプを持ち(つまり
relationType)、それがRDFでの矢印ラベル(=述語)に相当する
- RDF文のメタデータ記述拡張案RDF*(Turtle*)で記述してみると
<<jpsd:cobas-91058 schema:spatial place:三重>> jps:relationType role:発見.出土 ; schema:description "出土地: 伊勢国相可村" .
アクセス情報とメディアオブジェクト
- 取得タスクのための情報を集約
- 資料を所蔵している機関(
schema:provider) → 英文名称、緯度経度などを含む情報 - 提供機関の資料紹介/カタログURL(
schema:url)- IIIFマニフェストを含む、資料(のデジタル化オブジェクト)についての情報URL
- 資料のデジタル画像、音声動画など(
schema:associatedMedia)- 直接利用できる高解像度画像、動画、3Dオブジェクト、などを想定(現在のところ該当なし)
- サムネイル画像は共通情報(資料自身のプロパティ)として
schema:image
- 請求記号、展示番号など、資料閲覧のためのID
- 中間アグリゲータ(つなぎ役)が紹介ページを提供している場合、ソース情報も
schema:urlなどを持つ
- 資料を所蔵している機関(
- メディアオブジェクトのライセンス情報とメタデータ
- オブジェクトを主語としたトリプルで型、フォーマット、ライセンスなどを記述

- ライセンスは、提供者の基本ライセンスとしての提供が大半で、記述方法は要検討
- 現状では、利用者はライセンスを条件にしたアイテム/オブジェクト検索はできない
いつ:時間正規化と範囲検索
- 時間表記の正規化と実体化
- 時間記述はすべて年を単位に正規化
- 範囲を持つ時間実体(Interval)として表現。単年でも
start、endプロパティを持つ 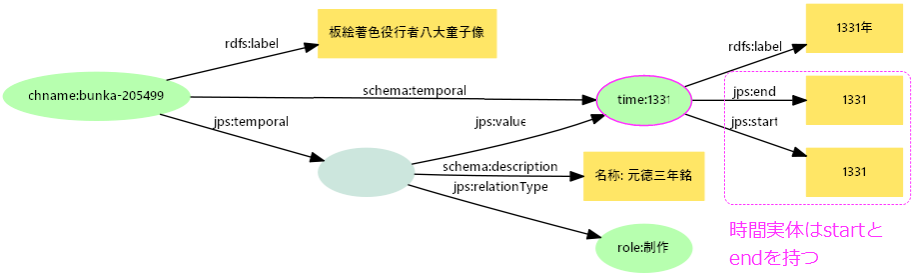
- 時代、世紀も同じ形で時間範囲実体として扱える。さらに曖昧年(○年代、189xなど)も
- 時間実体を利用して、異なる記述のアイテムを検索。例:鎌倉時代の絵画
- 「鎌倉時代」という時代表記の値だけでなく、その時代範囲の西暦、和暦記述も検索できる。
SELECT ?s ?start ?end WHERE { {time:鎌倉時代jps:start?st ;jps:end?et} ?s a type:絵画 ;schema:temporal[jps:start?start;jps:end?end ] . FILTER (?start >= ?st && ?end <= ?et) }- さらに年表上への表示も
どこ:位置情報の利用
- 都道府県単位の正規化
- 場所記述は粒度がさまざま(国単位~街区住所)。旧国名や市町村合併=現在使わない地名
- 都道府県を単位に正規化(海外は国単位)。
- たとえば検索結果を都道府県別に集計し地図を色分けするなど
- 緯度経度とGeohash
なに:グラフによる探索
- タイプと階層検索
- タイプは元データの「種別」などから生成 → データセットによって異なる
- クラスを階層化:「版画」「水彩」は「絵画」の一種
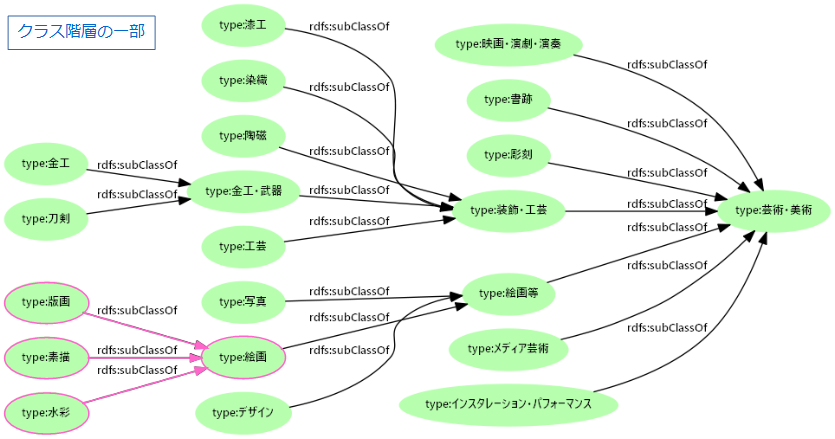
- クラス階層を利用して例えば神奈川県の絵画&サブクラスを検索(プロパティパス)
?type
rdfs:subClassOf*type:絵画
ジャパンサーチ内の新しい関係を見出す
- 作者関連グラフの推論
- アイテムにはしばしば複数寄与者 → これらの寄与者の間には何らかのつながりがある
SELECT ?someone (count(?s) as ?count) WHERE { ?sjps:agential[jps:relationType/skos:broader? role:制作; jps:value/owl:sameAs?chname:歌川広重], [jps:relationType/skos:broader? role:制作; jps:value?someone] FILTER(?someone != chname:歌川広重) } GROUP BY ?someone- つながりのある寄与者を集めることで、作者関連グラフが得られる
CONSRUCT句で関係を表すRDFグラフ生成もできるがここではつながりの数も考慮

注釈によるユーザ発信情報
- マイノートとWeb Annotation
- ジャパンサーチのマイノートは、利用者によるアイテムへの注釈と考えることができる
- この関係は、Web Annotationを用いて表現できる
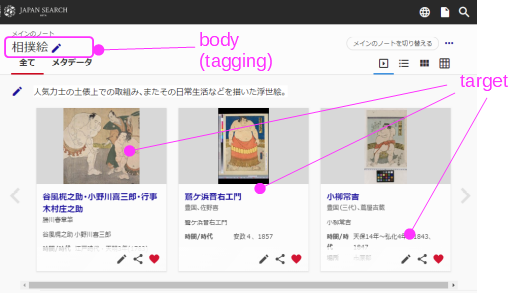
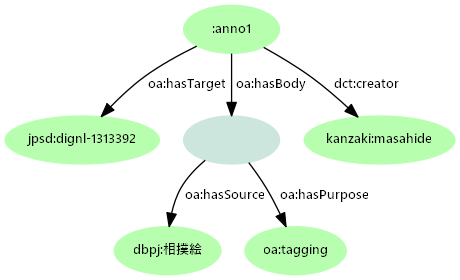
- Web Annotationで記述した注釈を用いて、ジャパンサーチとの統合クエリができる
- 自身のエンドポイントがなくても、ファイルに保存したWeb Annotationで統合クエリは可能
- ARQのようなコマンドラインツールで、ファイルを対象にクエリを実行できる
- URIハブとしてのジャパンサーチ
- 同じアイテムURIを
targetとして記述された注釈は集約が可能 - さまざまな注釈を集める第三者サービス=ユーザ発信情報との連携の可能性
- ただし同じ「作品」が複数アイテムに対応する場合があり、URIハブとして機能するにはそれらの集約が必要
- 同じアイテムURIを
データとしての利活用スキーマRDF
- メタデータはデータでもある
- 利活用スキーマRDFは、基本的にはアイテムを記述するメタデータ
- さらにメタデータ自体をデータとして分析対象にすることもできる
- 地図色分けやチャートはその一種でもあるが、視覚化表現からアイテム検索クエリにリンクしており、検索結果表現のインターフェイスの一種でもある
- タイトルなどのテキスト分析
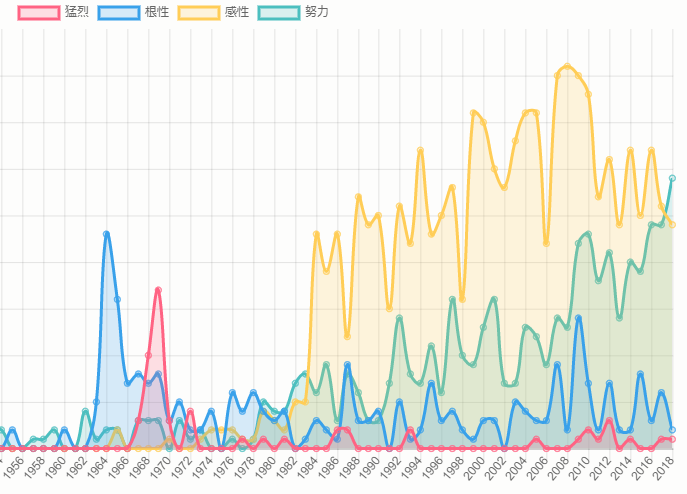
- キーワードをタイトルに含むアイテムを年別集計しグラフ化(例:猛烈,根性,感性,努力)
- タイトル抽出 → KH Coderで分析するなど
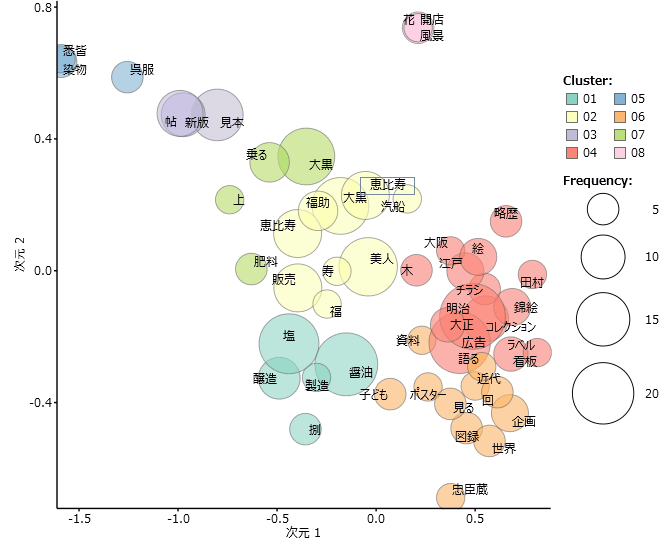
- 右図は「引札」を含むタイトルの多次元尺度法プロット