検索技術が創造する新たなコンテンツ
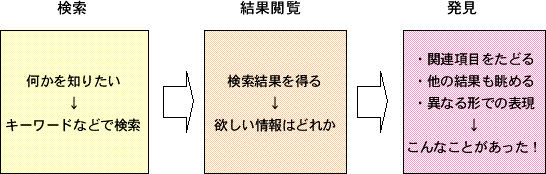
利用者から見た検索サービス
- さがす - たしかめる - 発見する
- 検索の過程で、ユーザの知識や意識などが変化していく
- 曖昧な状態から整理された状態、さらに新しい切り口へ
知りたいことを探す
- 資源発見のためのアクセスポイント
- どのような項目で検索ができるか
- 属性指定検索と全文検索
- キーワード(統制語彙 vs タグ)と分類
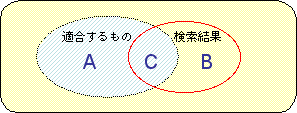
- 検索結果の指標
- 精度(pricision):検索結果のうち適合するものの割合
- 再現率(recall):適合するもの全てのうち、検索できた割合
- 精度と再現率は一般に反比例、何が「適合する」ものかは曖昧
全文検索と属性検索
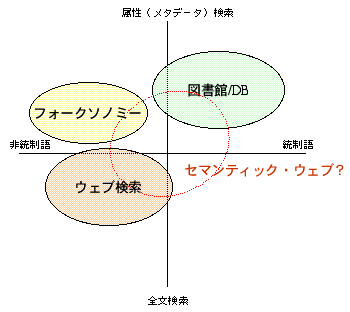
- 全文検索
- 一般に高再現率、低精度
- 大きなリソースを必要とするが、自動化しやすい
- 属性検索
- うまく使えば高精度。再現率は低くなる可能性
- 多くの資源に適切な属性値を与えるのは高コスト
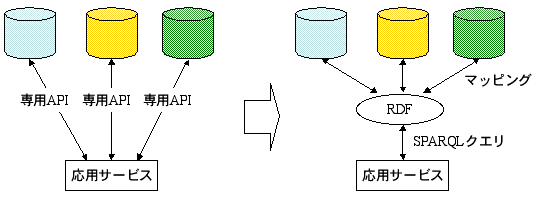
WSをつなぐSPARQLプロトコル
- やり取りのためのプロトコル規格も定義
- WSDL2.0に基づくHTTP、SOAPのバインディング
- ウェブサービス間の標準的な検索構築も可能